
BARNEY, 06/02/2022
El domingo pasado, tras la impresionante victoria (una más) de Rafa Nadal en la final del Open de Australia, recibí uno de los mejores memes de los últimos años, el que da inicio a este post. «Hola, soy Rafa Nadal y el big data me come los huevos». En esos momentos de partido, el programa de predicción de resultados del Open de Australia daba un 96 por ciento de posibilidades de victoria al ruso Daniil Medvedev y un exiguo 4 por ciento a Nadal. Los programas de las casas de apuestas le daban aún menos posibilidades, apenas un dos por ciento. Medvedev marchaba claramente por delante en el partido: dos sets a cero y 1-0 en el inicio del tercer set, y su ventaja parecía definitiva poco después:

Todos sabemos lo que ocurrió: Nadal salvó esos tres puntos de break, ganó el set, el cuarto, el quinto, el torneo y su 21º Grand Slam. Se agarró a ese cuatro por ciento de posibilidades y le dio la vuelta al partido. El Win Predictor es el resultado de un software desarrollado por Game Insight Group en colaboración con la federación australiana de tenis y la universidad de Victoria. El programa combina decenas de miles de resultados de partidos con estadísticas de los jugadores, los momentos de juego, incluso qué jugadores ganaban los puntos largos o cortos en el partido analizado. Todas las estadísticas estaban a favor de Medvedev y el programa informático se limitaba a contrastar los mismos:
- Medvedev tenía un 33-0 en partidos de Grand Slam tras llevarse los dos primeros sets.
- Nadal solo había remontado un 0-2 en sets en dos ocasiones en Grand Slam y de eso hacía muuuucho tiempo: ante Kendrick (Wimbledon, 2006) y ante Youzhny (Wimbledon, 2007). Yo le vi hacerlo otra vez, en el torneo de Madrid ante Ljubicic, una remontada impresionante e impensable tras los dos apabullantes primeros sets.
- Medvedev estaba dominando los puntos cortos en Melbourne, pero también los largos, los de más de nueve golpes, que suelen ser en los que Nadal cimenta sus triunfos.
- La edad de los jugadores, diez años más para el balear.
- Los resultados de los últimos meses: Medvedev fue el único que logró quebrar el año triunfal de Djokovic en 2021, mientras que Nadal acababa de salir de lesión y covid.
¿Falló el programa? En absoluto. Lo normal en esas circunstancias es que Medvedev se hubiera llevado el título, pero el factor humano, la cabeza unida a un inconmensurable talento, desmontaron lo que el big data se obstinaba en predecir. Hay detalles que un algoritmo posiblemente no pueda implementar, como la fortaleza mental. Los algoritmos funcionan y mejoran a medida que se les cargan más resultados y variables, pero hay algunos conceptos difícilmente valorables, como la competitividad del Big Three sobre la Next Gen. En la final de Roland Garros de 2021, Novak Djokovic remontó dos sets al griego Stefanos Tsitsipas. En la final del U.S. Open de 2019, Medvedev empató un partido casi perdido frente a Nadal, remontó dos sets a cero y break en contra, pero no remató. Casi remonta el partido, casi iguala el quinto, que perdía 5-2, pero todo fue «casi». Le faltó el punch final que sí tuvo Rafa. El talento del Big Three Nadal-Federer-Djokovic o Rafa-Roger-Nole sigue siendo superior a la Next Gen, que empieza a no ser tan joven: Medvedev cumple 26 esta semana (un US Open), Thiem tiene 28 y al igual, un US Open, Zverev cumple 25 en abril sin Grand Slams de momento y el griego Tsitsipas cuenta con 23 y una final perdida en Grand Slam.
El análisis masivo de datos, todas esas herramientas de business intelligence, machine learning, big data y demás, tienen gran utilidad para el mundo del deporte, pero por suerte nunca podrán predecir los resultados del deporte, siempre existirá esa «maravillosa impredecibilidad» que nos mantendrá pegados a la pantalla. El talento, al igual que el gen competitivo, es inconmensurable en el sentido estricto de la palabra: que no se puede medir, comprimir en un algoritmo matemático. Me recuerda a la escena de El club de los poetas muertos en la que el profesor Keating obliga a destrozar a los alumnos la página del libro en la que se hablaba de la poesía en términos matemáticos:
¡A la mierda todo eso, dejadme disfrutar del partido! Dejad que me recree en los momentos clave, en la brecha abierta en la ceja de Iván Drago que altera el desequilibrio de un encuentro y lo balancea hacia el extremo opuesto, dejad que las máquinas se vuelvan locas tratando de comprender lo incomprensible.
En las últimas décadas, el estudio del deporte a través de los datos está creciendo de manera exponencial. Existen escuelas de negocios cuyos equipos de análisis de datos trabajan con clubes de fútbol, baloncesto, ciclismo y casi cualquier especialidad profesional. En ocasiones no es necesario conocer bien el deporte, ni haberlo jugado siquiera, sino que a través del estudio riguroso de las estadísticas junto con los profesionales del deporte se pueden comprender mejor determinados aspectos del juego. La película Moneyball (2011, dirigida por Bennett Miller, con Brad Pitt, Jonah Hill y Philip Seymour Hoffman) cuenta la historia del gerente general de los Oakland Athletics de béisbol en 2002, cuando revolucionó este deporte con la ayuda de un friki de los datos sin apenas conocimiento del juego. Las estadísticas fueron utilizadas por Billy Beane (el personaje de Brad Pitt) para formar un equipo low cost que logró batir el récord de victorias consecutivas de la liga americana a base de cambiar algunos paradigmas del juego. El objetivo de algunos bateadores no era lograr la carrera, sino capturar la primera base, por ejemplo, o analizaban como los pitchers contrarios se desgastaban y perdían fuerza en los lanzamientos, por lo que se buscaba forzarlos para que perdieran esa potencia y precisión. Fue un cambio radical para un deporte que se había jugado durante décadas de la misma manera, con los mismos esquemas.


En Estados Unidos, en donde la profesionalización del deporte es exagerada en comparación con el resto del mundo, se analiza todo al detalle y los equipos de la NBA, la NFL o la MLB cuentan con potentes equipos de matemáticos, estadísticos o entrenadores formados en disciplinas relacionadas con el big data. Desde hace varios años, igual que se celebra la Super Bowl, el gran espectáculo del fútbol americano, los analistas del deporte se reúnen en la Big Data Bowl para hablar de los avances en el campo de la estadística aplicada al juego. Se mide todo: entrenamientos, forma física de los jugadores en cada momento concreto de la temporada, potencia y distancia de los lanzamientos, metros recorridos, velocidad de los jugadores, espacio que ocupan en defensa y ataque… Pero siguen buscando algo imposible: desarrollar herramientas predictivas.

En la NBA hay estudios muy interesantes (los programas de Antoni Daimiel son apasionantes cuando tocan estos asuntos) sobre la evolución del juego y los datos van mucho más allá de los tradicionales puntos+rebotes+asistencias:
- Cómo los jugadores se han ido alejando del aro a medida que aumentaban los porcentajes de tiro.
- Los cambios en las defensas en función de los jugadores exteriores rivales.
- Cómo los especialistas en la pintura ya no lanzan más allá de dos-tres metros.
- Los más/menos con determinado jugador en cancha, que puede medir una excesiva dependencia o todo lo contrario, un jugador muy bueno en lo individual que perjudica al conjunto.
- O esas otras que a veces lees en los rótulos en mitad de un partido: «2-15 cuando el equipo está con desventaja de 14 o más puntos», que en el caso de otros equipos puede demostrar una fortaleza mental muy superior: «8-12 cuando está abajo +14».
- Alguna vez he visto el porcentaje específico de tiros libres de un jugador en función de lo ajustado o no del marcador, un dato que puede ser más concluyentes que el simple «porcentaje de acierto».
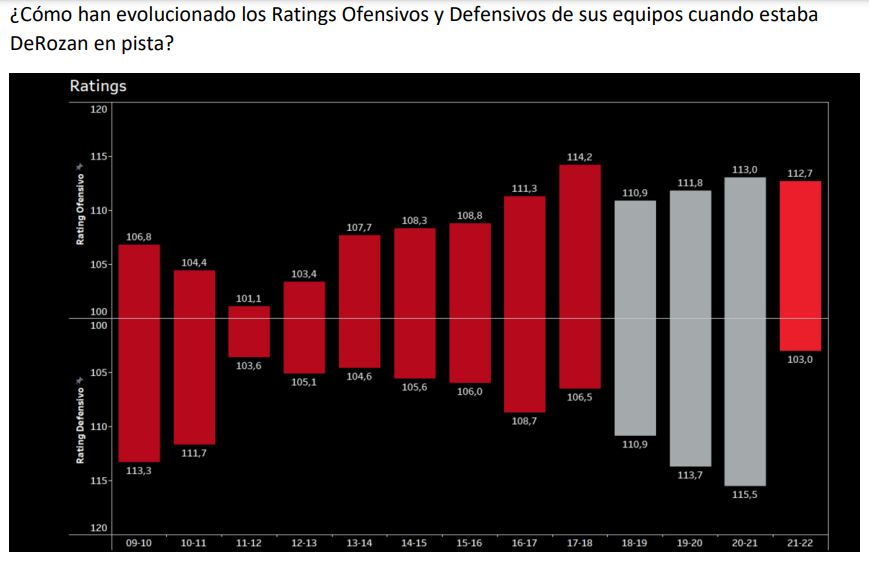
Yo personalmente tengo mis dudas al respecto: me interesan los datos como herramienta de análisis, pero no quiero saber de ellos para «manejar» un deporte, para tenerlo bajo control. Por llevarlo al extremo, no me interesa lo que ha ocurrido con el ciclismo o la Fórmula 1, deportes en los que parece que son los ordenadores los que previamente han decidido lo que va a ocurrir en la carrera. Los ciclistas y los pilotos están tan controlados en todos sus parámetros que los directores de equipo se limitan a transmitir por el pinganillo lo que las máquinas indican. Adiós a los arrebatos «a lo Perico Delgado», adiós a la emoción. Hay corrientes de aficionados al ciclismo en contra del uso del pinganillo y a favor de la vuelta al ciclismo tradicional. Ahora se habla más de vatios, potenciómetros y hasta ácido láctico. Yo era más de demarrajes irracionales y tirar hasta donde el cuerpo aguante.
En cuanto al fútbol, el big data se usa desde hace años, si bien en sus primeros pasos en nuestro país se utilizaba casi exclusivamente para el seguimiento de la forma física de los jugadores durante la temporada. Control del peso, mejora de la masa muscular, pérdida de grasa, minutos jugados, análisis de esfuerzo… Algunos entrenadores decidían las alineaciones en función de dichos parámetros y las famosas rotaciones eran resultado de los análisis de un ordenador.

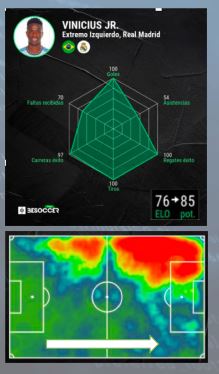
Según El Big Data y el Fútbol, en un partido se analizan unos ocho millones de datos. Repito, ocho millones. Datos que posteriormente se procesan y analizan, pero que nunca serán más fiables que un aficionado con una cerveza en la barra de un bar: «¡ejke no presionamos!». Los alumnos del Máster en Big Data Deportivo, certificado por la UCAM de Murcia y en colaboración con Opta (proveedor de datos de LaLiga), publican ocasionalmente sus informes en un blog de Marca. Suelen ser interesantes, si bien en ocasiones me parece que muchos de los datos son irrelevantes. O demuestran que el conocimiento de la estadística no va parejo con el del juego. Analizar todo esto, con mapa de calor incluido, para decir que Vinícius se desenvuelve mejor por la banda derecha es… en fin, erróneo.


En este enlace se puede acceder al vídeo QlikView y las estadísticas en el fútbol, en el que se dicen cosas interesantes como la enorme utilidad de los datos para el análisis a posteriori, pero sus limitaciones como herramienta de predicción. El fútbol sea quizás más impredecible que ningún otro deporte porque un solo gol puede decidirlo todo. «La sublimación del gol ha frenado el desarrollo de la estadística como herramienta de análisis», se dice en el vídeo. Me suena un poco Xavihernández («nos ganaron 7-0, pero tuvimos la posesión, no pudieron dominarnos»), pero lo cierto es que uno ve las estadísticas del Real Madrid-Sheriff Tiraspol de esta temporada (1-2), el Atlético de Madrid-Liverpool (1-0) o frente al Bayern de Múnich (1-0), o el Real Madrid-Bayern de 2014 (1-0) y resulta imposible prever que aquellos prtidos pudieran acabar con esos marcadores cuando los derrotados fueron superiores en todo lo demás: posesión, pases, acierto en los pases, tiros a puerta, jugadas en el área, ocasiones de gol, saques de esquina… Pero en ocasiones el portero o una gran defensa, o un acierto puntual en ataque revierten todo lo que la estadística indica.
Con el tiempo se avanza en el entendimiento del juego a través de la estadística y algunos talibanes de la posesión tendrán que comenzar a entender que esto consiste en meter goles, a veces de la manera más rápida, y no en sobar la pelota. Este vídeo habla de «Diez estadísticas del fútbol que la gente usa de manera errónea» y coincido con lo que indica acerca de que los datos por sí solos y sin conocimiento del contexto de juego no se utilizan correctamente:
Y luego están los «intangibles», como entender los diferentes criterios arbitrales. O por qué en cada partido la primera tarjeta es siempre para un jugador del Madrid. En el partido de cuartos de final de Copa de hace tres días, la primera falta del Madrid (Toni Kroos) fue sancionada con amarilla. Era clara, nada que objetar, lo que no es normal es que Raúl García llevara dos entradas de amarilla-naranja a esas alturas de partido y que se fuera de rositas del campo:

Como siempre que critico a ese carnicero llamado Raúl García me aparecen sus defensores para criticar a Sergio Ramos, les remito a una de las mejores página de estadísticas, FBREF.com, que tiene incluso la posibilidad de comparar jugadores y competiciones (siempre aparece con el duelo Messi-Cristiano por «el mejor de la historia») y yo he hecho la comparación entre ambos «tipos duros» y el doble rasero arbitral:

Son jugadores con más de diecisiete años en primera división, y mientras Raúl García ha hecho más faltas que Ramos (1050 frente a 962), ha recibido bastantes menos amarillas (142 frente a 175) y una cantidad ridícula de rojas (6+1 en lugar del récord de 21+4 de Ramos). Y eso que los datos no pueden medir la dureza de las entradas de uno y otro. Así que la próxima vez que alguien me hable de Ramos en el apartado disciplinario, le diré que con el big data en la mano, me puede comer los huevos.
Concluyo ya, casi como empezaba: el talento no podrá medirse o parametrizarse jamás. Dejo un vídeo de otro partido que vi en directo y que resultaba imposible predecir que acabaría como acabó: Brasil-Argentina del Mundial de Italia 90. Brasil dominó de principio a fin, tuvo muchas ocasiones claras, tiró tres veces al palo, pero… no pudo controlar una sola vez al genio, a Maradona, y perdió.
La maravillosa imprevisibilidad del deporte. Que siga, que las máquinas no nos limiten la capacidad de sorprendernos.
